《React设计原理》- 读书笔记
工程
目录结构
源码主要集中在react/packages中,核心功能相关模块如下
- shared: 公共模块包含了很多基本赖姓数据结构和公共方法以供其他模块使用
- react/src: react入口文件及api文件
- react-dom/src: react api入口文件
- react-dom/bindings: react api具体逻辑和合成事件逻辑
- react-reconciler/src: fiber架构协调相关逻辑
- scheduler/src: react调度相关逻辑
- react-is/src: react类型判断工具方法
- 其他略...
编译模式
使用前端框架时都需要编译这个步骤来将代码转换成宿主环境可是别的代码(vue > js、jsx > js)及压缩、混淆、优化,编译基本分为两类预编译(AOT)与即时编译(JIT)两者的区别在于:
JIT应用首次加载速度慢于AOT,前者需要先编译代码后者则使用提前编译完成的代码JIT因为需要运行时编译(包含compiler)代码量要大于AOT
框架类别
- 建立
状态与元素对应关系的框架,称为元素级框架(Svelte):用于在运行时建立自变量与因变量关系的细粒度更新 - 建立
状态与组件对应关系的框架,称为组件级框架(Vue):用于在编译时建立自变量与因变量关系的AOT - 建立
状态与应用对应关系的框架,称为应用级框架(React):用于在运行时实现根据自变量变化计算得出UI变化的VDOM
基于技术与分类标准,从偏向编译时还是运行时的角度看待框架:
Svelte是极致的编译时框架React是极致的运行时框架Vue3同时拥有两者的特性(AOT和VDOM),比较均衡
基础
React15因为更新流程一旦开始中途无法中断,基于这个原因React16重构了架构分别为:
React15Reconciler(协调器): VDOM的实现,负责根据自变量变化计算出UI变化Renderer(渲染器): 负责将有UI变化渲染到宿主环境中(mount的组件调用mountComponent、update的组件会调用updateComponent都会递归更新子组件,更新流程一旦开始无法中断)
Scheduler(调度器): 调度任务的优先级,高优先级任务优先进入ReconcilerReconciler(协调器): VDOM的实现,负责根据自变量变化计算出UI变化Renderer(渲染器): 负责将UI变化渲染到宿主环境中
随着React架构的重构,上层主打特性分为:
Sync(同步)Async Mode(异步模式)Concurrent Mode(并发模式)Concurrent Feature(并发特性)
旧架构对应同步时期,异步模式、并发模式、并发特性与新架构相关.重构后的Reconciler工作流从同步变为异步可中断,这一时期的React被称为Async Mode(异步模式)主要对解决了CPU瓶颈.而Concurrent Mode(并发模式:使用多个更新的工作流程并发执行)
渐进升级
为了React开发者在新旧版本之间实现平滑过度,React团队采用规范代码和不同情况的React共存的方式进行开发
- v16.3新增了
StrictMode在使用不符合并发更新规范的代码时(componentWillMount、componentWillReceiveProps、componentWillUpdate)给出警告并提示引导规范代码 - 新老架构经历了3中开发模式:
- Legacy模式,通过
ReactDOM.render(<App />, rootNode).默认关闭StrictMode(此模式未开启并发更新) - Blocking模式,通过
ReactDOM.createBlockingRoot(rootNode).render(<App />)作为从Legacy向Concurrent过度的中间模式,默认开启StrictMode(此模式未开启并发更新,但是启用了Automatic Batching新特性) - Concurrent模式,通过
ReactDOM.createRoot(rootNode).render(<App />)默认开启StrictMode(此模式已开启并发更新)
由于不同模式在迁移过程中的成本并没有达到渐进升级的目的,所以在v18版本不在提供三种开发模式而是以是否使用并发特性作为是否开启并发更的一句
位运算
React中大量使用二进制位运算来表示flags或者优先级,主要用到3种方式:
- 按位与(
&) 两个二进制操作数的每个bit都为1则结果为1 - 按位或(
|) 两个二进制操作数的每个bit都为0则结果为1 - 按位非(
~) 对一个二进制操作数逐位进行取反操作(0、1互换)
Fiber
fiber是react协调算法中执行渲染和更新过程时将任务细分成更小的工作单元,这些单独的工作单元可以被暂停、确定优先级、恢复使得react能更加灵活、高效的应对较为复杂ui场景
- 作为架构,v15的
Reconciler采用递归方式执行,被称为Stack Reconciler.v16及以后版本的Reconciler基于FiberNode实现被称为Fiber Reconciler - 作为静态数据结构,每个FiberNode对应一个React元素,用于保存React元素的类型、对应DOM元素等信息
- 作为动态的工作单元,每个FiberNode用于保存本次更新中该React元素变化的数据、要执行的工作(增、删、改、更新Ref、副作用等)
双缓存机制是指Fiber架构中同时存在两棵Fiber Tree一颗是真实UI对应的Fiber Tree可以理解为前缓冲区.另一颗是正在内存中构建的Fiber Tree可以理解为后缓冲区在VDOM结算后将wip(work in process)Fiber Tree和Current Fiber Tree作为交换并渲染到宿主环境
export type Fiber = { tag: WorkTag, // fiber节点标签一共27种,不同类型对应不同的渲染方式(类组件、函数组件等) key: null | string, // 标识子节点唯一性的key值 elementType: any, // 在diff中两key值不相同时生成新节点时用作记录类型的值,当处理完成后与type值一致 type: any, // 元素类型 stateNode: any, // 根据当前状态所下对应的节点 return: Fiber | null, // 当前正在处理的父级节点 child: Fiber | null, // 子节点 sibling: Fiber | null, // 相邻兄弟节点 index: number, // 标记节点在当前层级的位置 ref: // 最终附加到原生dom节点的引用 | null | (((handle: mixed) => void) & {_stringRef: ?string, ...}) | RefObject, pendingProps: any, // 处理中未确定的属性 memoizedProps: any, // 处理后对应的属性 updateQueue: mixed, // 批量处理队列 memoizedState: any, // 处理后对应的状态 dependencies: Dependencies | null, // context跨组件传值时的依赖 mode: TypeOfMode, flags: Flags, // 由16位二进制组合而成的副作用标记 subtreeFlags: Flags, deletions: Array<Fiber> | null, // 要被删除的子节点 nextEffect: Fiber | null, // 下一个副作用 firstEffect: Fiber | null, // 第一个副作用 lastEffect: Fiber | null, // 最后一个副作用 lanes: Lanes, // 优先调度有关 childLanes: Lanes, alternate: Fiber | null, // 新老节点对比时缓存节点 // 开发调试时的系列时间 actualDuration?: number, actualStartTime?: number, selfBaseDuration?: number, treeBaseDuration?: number, // ...};时间切片
Time Slice将运行时VDOM操作(VDOM在React中的实现)拆解为多个不会造成掉帧的短宏任务,每次循环都会调用shouldYield(当前时间是否大于过期时间 )判断当前Time Slice是否有剩余时间,没有剩余时间则暂停更新流程,将主线程交给渲染流水线,等待下一个宏任务再继续执行
优先级
- 为不同操作造成的自变量变化赋予不同优先级
- 所有优先级统一调度,优先处理最高优先级的更新
- 如果正在进行(VDOM相关工作),有更高优先级的更新产生,则会中断当前更新,预先处理高优先级的更新
上述三个要点,需要React底层实现:
- 用于调度优先级的调度器
- 用于调度器的调度算法
- 支持可中断的VDOM实现
架构
React更新流程: Schedual接收到更新开始调度 > Reconciler接收到更新计算更新造成的影响并将计算结果交给 > Renderer接收到更新,根据副作用标记执行对应操作
Schedual和Reconciler都在内存中进行不会更新宿主环境UI,因此即使工作流程反复中断,用户也不会看到更新不完全的UI
工作流程中可被打断的原因:
- 有其他更高优先级任务需要先执行
- 当前
Time Slice没有剩余时间 - 发生错误
render阶段
根据Scheduler调度的结果不同,render阶段可能开始于performSync WokOnRoot(同步更新流程)或performConcurrentWorkOnRoot(并发更新流程)方法.
// performSyncWorkOnRootfunction workLoopSync() { while (workInProgress !== null) { performUnitOfWork(workInProgress) }}
// performConcurrentWorkOnRootfunction workLoopConcurrent() { while (workInProgress !== null && !shouldYield()) { performUnitOfWork(workInProgress) }}performUnitOfWork方法会创建下一个fiberNode并赋值给wip,并将wip与已创建的fiberNode连接起来构成Fiber Tree,wip === null代表Fiber Tree的构建工作结束.同步和异步执行任务的区别就在于是否可中断
performUnitOfWork会从HostRootFiber开始向下以DFS的方式遍历进行递操作为遍历到的每个fiberNode执行beginWork方法,该方法会根据传入的fiberNode创建下一级fiberNode直至遍历到叶子元素(不包含子fiberNode)时,
performanceUnitOfWork就会执行归操作调用completeWork方法处理fiberNode如果其存在兄弟fiberNode则会重复前面的递操作遍历直至fiberNode.sibling === null则进入父fiberNode的归操作.
<ul> <li></li> <li></li> <li></li></ul>
// 子fiber节点依次连接后并归还父fiber节点-=LI0Fiber.sibling = LI1Fiber;LI1Fiber.sibling = LI2Fiber;LI0Fiber.return = ULFiber;递阶段和归阶段会交错执行至HostRootFiber的归阶段至此render阶段的工作结束
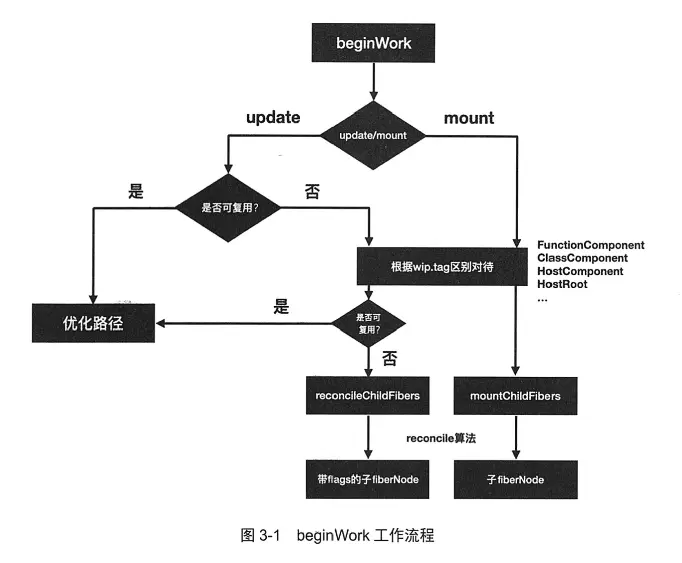
beginWork根据Current fiberNode是否存在分为update和mount流程,如果无法复用Current fiberNode两者大体一致:
- 根据
wip.tag进行不同类型元素的处理分支(FunctionComponent、ClassComponent、HostComponent、HostRoot) - 使用
reconcile算法生成下一级fiberNode
两个流程的区别在于最终是否会为生成的子fiberNode标记副作用flags,update时调用reconcileChildFibers需要追踪副作用并标记flags,mount时调用mountChildFibers则不需要
completeWork与beginWork类似,completeWork也会根据wip.tag区别对待,并对前者的fiberNode的插入、删除、移动操作进行完成标记,流程包括两个步骤:
- 创建或者标记元素更新
- flags冒泡
flags冒泡(自下而上的将子孙节点中标记flags向上冒泡一层)用于将散落在Wip Fiber Tree各处的被标记的fiberNode进行DOM操作,当HostRootFiber完成completeWork,整棵Wip Fiber Tree中所有被标记的flags都在HostRootFiber.subtreeFlags中定义.
在Renderer中通过任意一级fiberNode.subtreeFlags都可以快速确定该fiberNode所在子树是否存在副作用需要执行
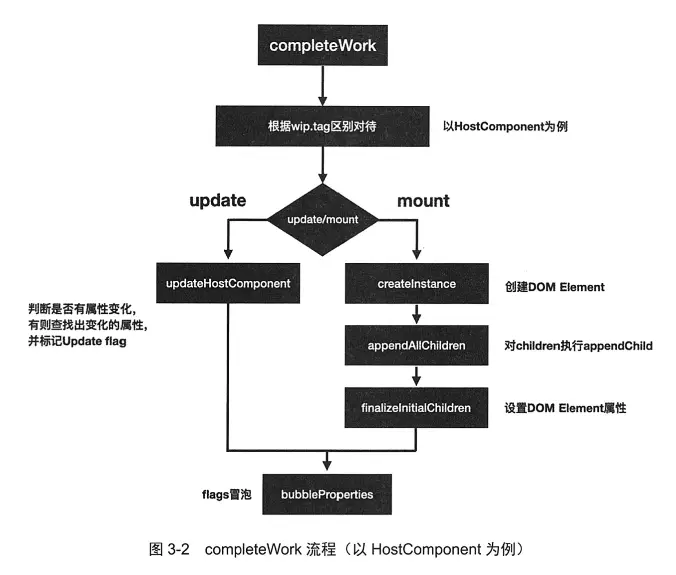
completeWork在mount时的流程总结如下:
- 根据
wip.tag进入不同处理分支 - 根据
current !== null区分mount与update流程 - 对于
HostComponent,首先执行createInstance方法创建对应的DOM元素 - 执行
appendAllChildren将下一级DOM元素挂在步骤3创建的DOM元素下 - 执行
finalizeInitialChildren完成属性初始化 - 执行
bubbleProperties完成flags冒泡
completeWork在update时的流程:
- 第一次遍历,标记删除
更新前有,更新后没有的属性 - 第二次遍历,标记更新
update流程前后发生改变的属性
Reconciler render阶段总结:它采用DFS的顺序构建Wip Fiber Tree,更个过程可以划分为递和归两个阶段,分别对应beginWork和completeWork方法
beginWork根据当前fiberNode创建下一级fiberNode在update时标记Placement(新增、移动)、ChildDeletion(删除)completeWork在mount时会构建DOM Tree,初始化属性,在update时标记Update(属性更新),最终执行flags冒泡
当最终HostRootFiber完成completeWork时,Reconciler的工作流程结束,此时得到:代表本次更新的Wip Fiber Tree和被标记的flags,HostRootFiber对应的FiberRootNode会被传递给Renderer进行下一阶段工作
commit阶段
render阶段流程可能被打断,而commit阶段一旦开始就会同步执行直到完成,整个阶段可以分为三个子阶段:
BeforeMutation阶段Mutation阶段Layout阶段
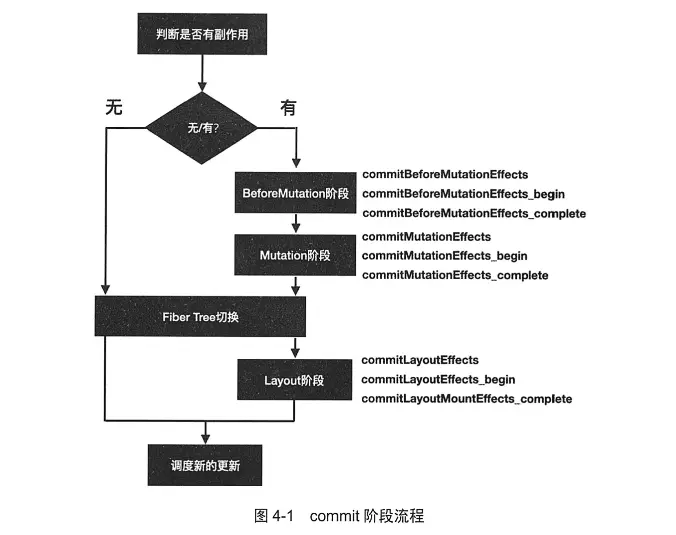
Renderer commit阶段流程总结:可以分为三个阶段:
- 开始前的准备工作,比如判断是否有副作用需要执行
- 处理副作用
-
BeforeMutation阶段 - commitBeforeMutationEffects
- commitBeforeMutationEffects_begin
-
commitBeforeMutationEffects_complete
Mutation阶段(Fiber Tree)的切换会在Mutation阶段完成后,Layout阶段还未开始前执行
- commitMutationEffects
- commitMutationEffects_begin
-
commitMutationEffects_complete
Layout阶段
- commitLayoutEffects
- commitLayoutEffects_begin
- commitLayoutEffects_complete
- 结束后的首位工作,比如调度新的更新
Scheduler阶段
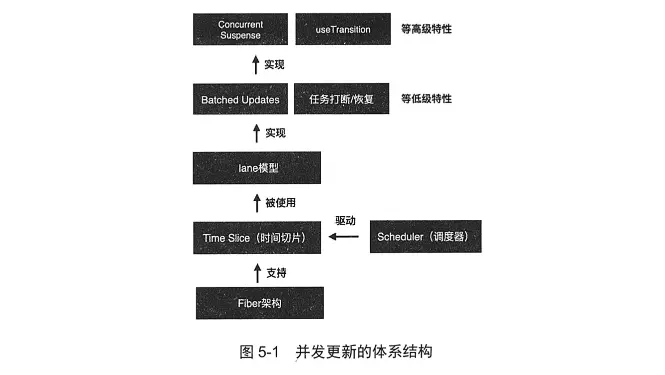
Scheduler为Time Slice分割出一个个短宏任务提供了执行的驱动力,为了更灵活地控制宏任务的执行时机,React实现了一套基于Lane模型的优先级算法,并基于这套算法实现了Batched Updates(批量更新)、任务打断/恢复机制等低级特性(不合适开发者直接控制,一般由React统一管理).基于低级特性,React实现了面向开发者的高级特性(并发特性),比如Concurrent Suspense、useTransition
Schedualer预置了5种优先级,优先级依次降低:
ImmediatePriority(最高优先级,同步执行)UserBlockingPriorityNormalPriorityLowPriorityIdlePriority(最低优先级)
设置优先级的目的是为了高效、快速的优先级计算和高可扩展性,Schedualer对外导出的schedualeCallback方法接收优先级与回调函数fn,在内部执行后会生成task数据结构代表一个被调度的任务
scheduleCallback(LowPriority, perform.bind(null, work))
const task = { // startTime为执行此回调时的当前时间,如果传递了delay参数则会在此基础上增加延迟时间 // timeout为不同优先级对应不同的timeout expirationTime: startTime + timeout, callback: perform.bind(null, work)}优先级值越小优先级越高,高优先级的task.callback在新的宏任务中优先执行.work根据其count属性可以被执行一次或数次,当预留给当前callback的时间用尽时shouldYield() === true循环中断有两种情况造成这种局面:
- 工作太多
- 单次工作耗时过多
当work.priority === ImmediatePriority || didTimeout条件成立时work对应工作不会中断而是同步执行直到work.count耗尽
当执行优先级低于ImmediatePriority的work时
当执行优先级与ImmediatePriority相同的work时
当低优先级work执行过程中插入高优先级work时
当高优先级work执行过程中插入低于或等于其优先级的work时
delay代表task需要延迟执行的时间,不是所有task都会配置delay没有配置的task会直接进入task queue.expirationTime会作为排序依据,值越小优先级越高.除此之外其主要作用是为了解决饥饿问题,所以可以得出:
- 配置delay且未到期的task一定不会执行
- 配置delay且未到期或者未配置delay的task根据task.expiration排序调度并执行,过期task执行时不会被打断
Schedualer作为一个独立的包处于通用型考虑并不与React公用一套优先级体系,不同交互对应的事件回调中产生的update会拥有不同的优先级,由于优先级与事件相关所以被称为EventPriority(事件优先级)有四种:
const DiscreteEventPriority = SyncLane对应离散事件的优先级,click、input、focus、blur、touchstart等const ContinuousEventPriority = InputContinuousLane对应连续事件的优先级,drag、mousemove、scroll、touchmove、wheel等const DefaultEventPriority = DefaultLane对应默认优先级,例如通过计时器周期性触发更新,这种情况产生的update不属于交互式产生的update所以时默认优先级const IdleEventPriority = IdleLane对应空闲情况的优先级
Schedule阶段总结由以下部分组成:
- 执行的动力-
Scheduler - 执行的底层算法-
lane模型 - 执行的策略-调度策略
- 执行的边界情况-饥饿问题
- 低级特性-
Batched Updates等 - 高级特性-各种
Concurrent Feature
实现细节
状态更新流程
lane与UI的关系通过如下方式建立:
- lane与update相关
- update与state相关
- state与UI相关
交互初始化更新想关系主要包括三类信息:
- lane优先级信息
- 更新对应数据结构Update
- 交互发生的时间
以FC为例,Update数据结构如下:
const update = { lane, // 对应lane action, // 改变state的方法 hasEagerState: false, // 性能优化相关字段 eagerState: null, next: null // 与其他update连接形成环状链表}在render阶段beginWork中,基于workInProgressRootRenderLanes中包含的lane,选择fiberNode中包含对应lane的update,并基于这些update计算出state.这就建立了update与state的联系
基于state计算出UI变化,以subtreeFlags的形式保存.最终commit阶段,基于subtreeFlags将变化渲染到UI中.这就建立了state与UI的联系.
事件系统
更新流程由产生交互开发,交互则与各种事件相关,事件由React事件系统产生.事件系统存在的意义在于:React用Fiber Tree这一数据结构描述UI,事件系统则基于Fiber Tree描述UI交互,对于ReactDOM宿主环境,这套事件系统由两部分组成:
SyntheticEvent(合成事件):是对浏览器原生事件的一层封装(与原生事件相同的api、兼容性处理),对于浏览器不支持的事件可以通过扩展的方式增加- 模拟实现事件传播机制:利用事件委托的原理,React基于Fiber Tree实现了事件的捕获、目标、冒泡流程,并在这个事件传播机制中加入了许多新特性,比如:
- 不同事件对应不同优先级
- 定制事件名称(onXXX > onClickCapture)
- 定义事件行为(onChange默认行为与原声oninput相同)
可以冒泡的事件传播机制的实现步骤如下:
- 在根元素绑定事件类型对应的事件回调,所有子孙元素触发该类事件最终都会委托给根元素的事件回调处理
- 寻找触发事件的DOM元素,找到其对应的
fiberNode - 收集从当前
fiberNode到HostRoosFiber之间所有注册的该事件的回调函数 - 反向遍历并执行一遍收集的所有回调函数(模拟捕获阶段的实现)
- 正向遍历并执行一遍收集的所有回调函数(模拟冒泡阶段的实现)
class SyntheticEvent { constructor(e) { this.nativeEvent = e } stopPropagation() { this._stopPropagation = true if (this.nativeEvent.stopPropagation) { this.nativeEvent.stopPropagation } }}
const addEvent = (container, type) => { container.addEventListener(type, e => { _dispatchEvent(e, type.toUpperCase(), container) })}
const root = document.querySelector('#root')ReactDom.createRoot(root).render(jsx)
addEvent(root, 'click')
const _dispatchEvent = (e, type) => { const se = new SyntheticEvent(e) const ele = e.target
// 步骤2:通过DOM元素找到对应的fiberNode let fiber; for (let prop in ele) { if (prop.toLowerCase().includes('fiber')) { fiber = ele[prop] } }
// 由于是从目标fiberNode向上遍历,一次收集的顺序为 // [目标事件回调, 某个祖先事件回调, 某个更久远的祖先回调...] const paths = _collectPath(type, fiber)
triggerEventFlow(paths, type + "CAPTURE", se)
if (!se._stopPropagation) { triggerEventFlow(paths.reverse(), type, se) }}
const _collectPath = (type, begin) => { const paths = [] while (begin.tag !== 3) { // 如果不是HostRootFiber就一直向上遍历 const { memoizedProps, tag } = begin if (tag === 5) { // 5代表DOM元素对应fiberNode const eventName = ("on" + type).toUpperCase() if (memoizedProps && Object.keys(memoizedProps).includes(eventName)) { const pathNode = {} pathNode[type.toUpperCase()] = memoizedProps[eventName] paths.push(pathNode) } } begin = begin.return } return paths}
const triggerEventFlow = (paths, type, se) => { for (let i = paths.length; i--;) { const pathNode = paths[i] const callback = pathNode[type] if (callback) callback.call(null, se) if (se._stopPropagation) break; }}在此基础上,事件类型很容易与优先级产生关联,进而与时间回调触发的更新对应的lane产生关联
Update
触发状态更新的方法有很多,虽然这些方法执行场景不同,但是都可以介入同样的更新流程原因在于他们使用同一种数据结构代表更新,这就是Update.FiberNode中存在多种tag,对应不同功能的组件所以同一字段在不同及诶单中有着不同的作用,甚至不同的数据结构
ReactDOM.createRoot>HostRootthis.setState>ClassComponentthis.forceUpdate>ClassComponentuseState dispatcher>FunctionComponentuseReducer dispatcher>FunctionComponent
tag字段用于区分触发更新的场景,可选项包括:
ReplaceState代表在ClassComponent生命周期函数中直接改变this.stateUpdateState代表默认情况,通过ReactDOM.createRoot或this.setState触发更新CaptureUpdate代表发生错误的情况下在ClassComponent或HostRoot中触发更新(getDerivedSateFromError)ForceUpdate代表通过this.forceUpdate触发更新
update的紧急程度由lane字段表示,update之间的顺序由next字段表示.update.next只想下一个update,构成一条环形链表
updateQueue时保存参与state计算的相关数据的数据结构,与update类似updateQueue在不同类型的fiberNode中也有不同的数据结构
const updateQueue = { baseState: null, // 参与计算的初始state // 本次更新前该fiberNode以链表形式保存的update firstBaseUpdate: null, // 表头 lastBaseUpdate: null, // 表尾 shared: { pending: null // 触发更新后产生的update会保存在shared.pending中形成单向环状链表 }}state计算的流程可以概括为两步,计算后的state被称为memoizedState
- 将baseUpdate与shared.pending拼接成新链表
- 遍历拼接后的新链表,根据workInProgressRootRenderLanes选定的优先级,基于符合优先级条件的update计算state
按场景划分update的产生有三类:
非React工作流程内产生的update,比如交互触发的更新RenderPhaseUpdate,render阶段产生的update,如UNSAFE_componentWillReceiveProps方法内的更新InterleavedUpdate,除render阶段外在React工作流程其他阶段产生的update
当fiberNode中产生update时,有下面两种情况:
- 当fiberNode中不存在未被消费的update,则该update会与自身形成环状链表
- 当fiberNode中存在未被消费的update组成的环状链表,则将新update插入该链表中
let pending = shared.pending
if (pending === null) { update.next = update} else { update.next = pending.next pending.next = update}
shared.pending = updateshared.pending始终指向最后插入的update,shared.pending.next始终指向第一个插入的update
与fiber架构的双缓存机制类似,Hook也存在current Hook与wip Hook.从hook的角度上看,update的消费过程如下:
- wip Hook的pendingQueue(类似shared.pending)与current Hook的baseQueue(类似baseUpdate)完成拼接,保存在currentHook中
- 遍历步骤1拼接完成的baseQueue链表,计算state,该过程中会根据update的消费情况形成新的baseQueue链表
- 将步骤2形成的baseQueue链表保存在wip Hook中
拼接完成的baseQueue链表保存在current Hook中,而消费完成的baseQueue链表保存在wip Hook中.只要commit阶段还未完成,current与wip就不会互换.所以即使经历多次render阶段也可以从current Hook中恢复完整的update链表
计算过程中是否有update被跳过包括两种情况:
- newBaseQueueLast为null,代表计算过程中没有update被跳过则计算出的state为最终state,此时memoizedState与newBaseState一致
- 计算过程中有update被跳过,计算出state为中间state,此时memoizedState与newBaseState不一致,未参与计算的update保存在baseQueue中
当优先级不足时(isSubsetOfLanes(renderLanes, updateLane)),会执行如下操作:
- 克隆当前update,加入newBaseQueue
- 如果当前update是一个被跳过的update,则更新newBaseState
- 将beginWork中消费的lane重置
当优先级足够时,会执行如下操作:
- 如果存在被跳过的update,则克隆当前update并加入newBaseQueue
- 计算stat
根据优先级不足时的步骤2得知下次更新的baseState取决于上次更新中第一次跳过的update时已经计算出的state,为了计算最终state需要被条过的update及其后面的所有update都参与计算.
即使当前update优先级足够,只要在此之前存在被条过的update,就需要克隆当前update并加入newBaseQueue,同时赋值update.lane=NoLane(因为NoLane属于热河lanes的集合),无论下次更新优先级如何,该update都会在下次更新中参与计算(如果update曾命中eagerState优化策略,则无需计算即可获取当前state)
ReactDOM.createRoot
ReactDOM.createRoot(root)执行后返回reactDOMRoot,reactDOMRoot.render(<app/>)执行后会开启首屏渲染流程
性能优化API:
- shouldComponentUpdate
- PureComponent
- React.memo
- useMemo、useCallback
性能优化的两个方向:
- 编写符合性能优化策略的组件,命中策略
- 调用性能优化API,命中策略
eagerState策略:如果某个状态更新前后没有变化(Object.is(eagerState, memoizedState)),则可以跳过后续更新流程.急迫的state表示在当前fiberNode不存在待执行的更新的情况下,可以将这一计算过程提前到schedule阶段之前执行.策略的前提条件之所以是当前fiberNode不存在待执行的更新,是因为这种强况下的触发更新产生的udate是当前fiberNode中第一个待执行的更新,计算state时不会受其他update的影响
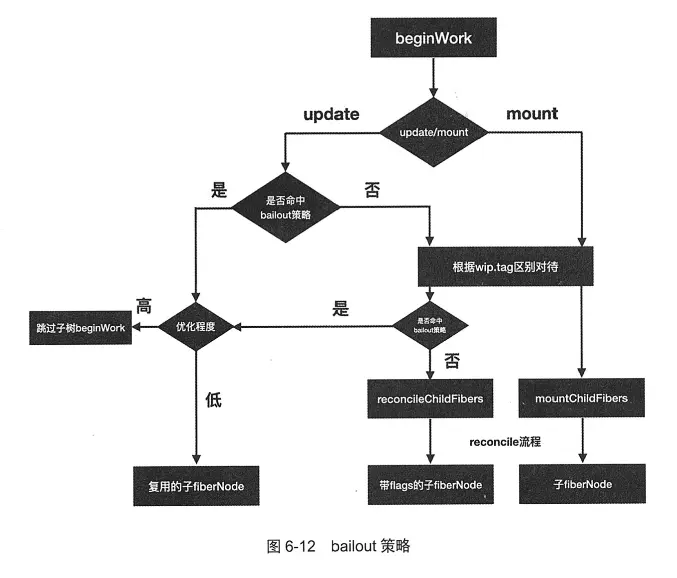
bailout策略:beginWork的目的是生成wip fiberNode的子fiberNode,实现这个目的存在两条路径:
- 通过reconcile流程生成子fiberNode
- 通过bailout策略复用fiberNode
是否命中bailout策略表示子fiberNode没有变化(state, props, context)可以复用,进入beginWork后有两次是否命中bailout策略相关的判断:
- oldProps === newProps(这个全等判断表示只有当父fiberNode命中bailout策略复用子fiberNode时才满足)
- Legacy Context(旧的Context API)没有变化
- fiberNode.type没有变化(div > ul)
- 当前fiberNode没有更新发生(有更新发生并不以为着state一定会变化)
编写符合性能优化条件的组件方式本质都是将可变部分(state、props、context)与不可变部分分离,使不可变部分能够命中bailout策略.即使不使用性能优化api合理的组件结构也能为性能助力
状态更新流程总结:在React中,事件在时间系统中传播,不同事件中触发的更新拥有不同优先级.更新对应数据结构Update它将参与计算state.
在触发更新时存在一种性能优化策略eagerState.进入render阶段后存在一种性能优化策略-bailout它有两种优化成都:
- 复用子fiberNode
- 跳过子树的beginWork
没有命中bailout策略,在render阶段的beginWork中,会进入reconcile流程
Reconcile流程
在beginWork中没有命中bailout策略的fiberNode会根据所处阶段不同(mount、update)进入mountChildFibers或reconcileChildFibers它们的区别在于是否追踪副作用(是否标记flags)这一流程被称为reconcile流程.对于一个DOM元素在某一时刻最多会有三个节点与它相关:
- current fiberNode与视图中的DOM元素对应
- wip fiberNode与更新流程中的DOM元素对应
- JSX对象描述DOM元素所需数据
reconcile流程的本质时对比current fiberNode与JSX对象生成wip fiberNode这一流程的核心算法被称Diff算法.因其O(n^3)复杂度性能开销过于高昂,React的Diff算法会预设三个限制:
- 只对同级元素进行Diff.如果一个DOM元素在前后两次更新中跨越了层级那么将不尝试复用它
- 两个不同类型的元素会产生不同的树.如果元素由DIV编程P,React会销毁DIV及其子孙元素并新建P及其子孙元素
- 开发者通过Key来暗示哪些子元素在不同的渲染下能够保持稳定(根据key来判断是否复用)
根据第一条限制规则可以将diff流程分为两类:
- 当newChild类型为object、number、string时,代表更新后同级只有一个元素,此时会根据newChild创建wip fiberNode并返回wip fiberNode
- 当newChild类型为Array、iterator,代表更新后同级有多个元素,此时会遍历newChild创建wip fiberNode及其兄弟fiberNode并返回wip fiberNode
单点节点Diff:对应JSX类型的REACT_ELEMENT_TYPE,在reconcileChildFibers方法中执行reconcileSingleElement
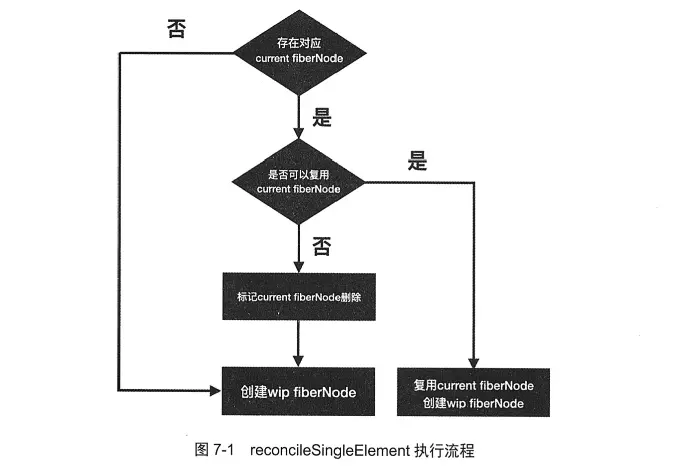
reconcile流程对比current fiberNode与JSX对象,生成wip fiberNode.执行reconcileSingleElement到表更新后同级只有一个JSX对象,而current fiberNode可能存在兄弟fiberNode所以需要遍历current fiberNode及其兄弟节点寻找可复用的fiberNode.判断是否可复用遵循如下顺序
- 判断key是否相同,如果更新前后均未设置key,则key均为null,也属于相同的情况
- 如果key相同,再判断type是否相同,当以上条件均满足,则current fiberNode可以复用.但也有细节需要关注
- 当child!==null且key相同且type不同时,执行deleteRemainingChildren将child及其兄弟fiberNode均标记删除
- 当child!==null且keY不同时,仅将child标记删除
多节点Diff:通过reconcileChildFibers处理,newChild类型为Array.同级多节点diff包含三种情况
- 节点位置没有变化
- 节点增删
- 节点移动
参与比较的双方,oldFiber代表current fiberNode,其数据结构是链表.newChildren代表JSX对象,其数据结构是数组.由于oldFiber链表结构无法借助双指针从数据首尾同时遍历以提高效率.vue的Diff算法中的倒叙遍历节点也不适用于React
Diff算法设计思路:
- 判断当前节点属于哪些情况
- 如果时增删,执行增删逻辑
- 如果位置没有变化,执行相应逻辑
- 如果时移动,执行移动逻辑
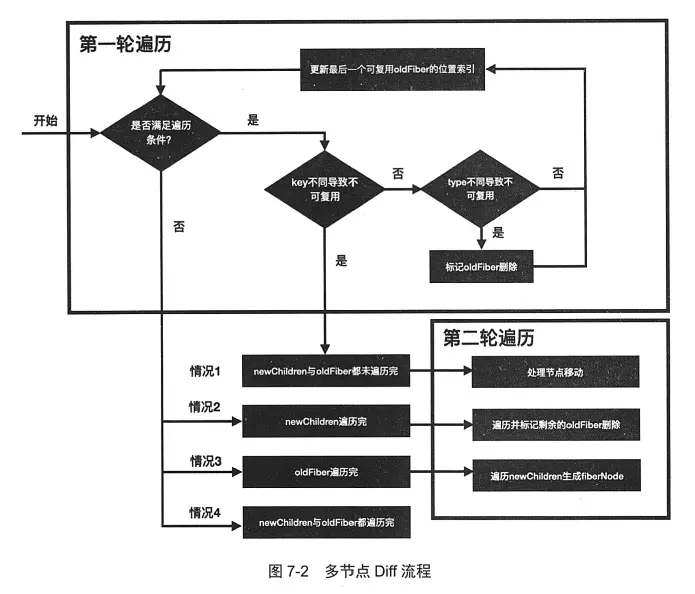
Diff算法整体逻辑经历两轮遍历:
- 第一轮遍历尝试逐个复用节点
- 遍历
newChildren将newChildren[newIdx]与oldFiber比较,判断是否可复用 - 如果可以复用继续步骤1,如果不可以复用则分两种情况:
- key不同导致不可复用,立即跳出遍历,第一轮遍历结束
- key相同type不同导致不可复用,会将oldFiber标记为DELETION继续步骤1
- 如果newChildren遍历完或者oldFiber遍历完则跳出遍历,第一轮遍历结束
- newChildren遍历完oldChildren未遍历完意味着旧节点需要被删除,遍历其余oldFiber依次标记Deletion
- oldFiber遍历完newChildren未遍历完,意味着有新节点被插入,需要遍历其余newChildren依次生成fiberNode
- 第二轮遍历处理剩下的节点
Diff算法的核心逻辑包括三个步骤:
- 遍历前的准备工作:将before中每个node保存在以node.key为key,node为value的map中,以O(1)复杂度可以通过key找到before中对应的node
- 核心遍历逻辑:当遍历after如果一个node同时存在与before与after(key相同),我们称这个node可以复用那么本次更新一定属于(不移动、移动)根据before节点索引和最后一次移动索引做比较进行对应移动逻辑
- 遍历后的收尾工作:经过遍历如果beforeMap中还剩下node则表示这些node无法复用则需要标记删除
reconcile流程总结:render阶段每个fiberNode都要经历bailout、reconcile流程,reconcile流程通过对比current fiberNode与JSX对象,生成wip fiberNode.reconcile流程的核心逻辑是Diff算法,根据参与比较的JSX对象数量不同可以将Diff算法分成:
- 单节点Diff
- 节点复用问题
- 多余节点删除
- 多节点Diff
- 节点复用问题
- 节点的增删
- 节点的移动
FC & Hooks
ClassComponent类组件面临的问题:
- 业务逻辑分散:业务逻辑分散在不同生命周期函数中,这不仅会造成同一生命周期函数中包含多种不相关的逻辑,也会造成同一逻辑被分割到不同生命周期函数中.组件愈发复杂,这个问题会愈发严重
- 有状态的逻辑复用困难:当逻辑被分割到不同生命周期函数后,很难跨组建复用有状态的逻辑.虽然先后提出了
render props和HOC但也为组件结构引入了新的复杂度
代数效应是函数编程中的一个概念,用于将副作用从函数调用中分离.只要遵循一定规范,在FC中可以不区分同步、异步以同样的方式从数据源中获取数据.基于这个设定所有从数据源获取数据的操作都可以收敛到这套代数效应的实现中
代数效应在React中的应用需要Suspense来处理视图的pending状态.除代数效应这一应用场景外,Suspense还有如下多种应用场景:
React.lazy:当使用Webpack等构建工具实现动态import时,加载动态组件会发起一个JSONP请求,当请求返回前,UI的中间状态会交由组件树中离动态组件最近的Suspense处理startTransition:使用它可以降低本次更新的优先级,React会保留旧的UI,并等待新的UI完成Server Components:在服务端运行的组件获取数据后会在服务端与客户端之间以序列化的JSX格式流式传输.传输过程中UI的中间状态会交由Suspense处理Selective Hydration:采用SSR服务端输出的是HTML字符串,浏览器会根据这些HTML结构完成React初始化工作(创建FiberTree、绑定事件)这个过程被称为Hydration.但其有两个缺点:
- 页面中不同组成部分展示优先级是有差异的,但Hydration对他们一视同仁
- 整个应用Hydrate工作全部完成后,UI的任意部分才能交互
Selective Hydration使用Suspense选择性包裹为Hydration划分粒度,使高优先级部分优先展示.此外,当Hydration流程进行时,Suspense能够使产生用户交互的部分优先Hydrate
通常来说beginWork的返回值是wip.child,而Suspense对应beginWork的返回值可能并不是wip.child,而是:
- 当Suspense处于suspend(挂起状态)时,存在
Offscreen与fallbackFragment两个child.对于Offscreen,其props.mode === 'hidden'对应beginWork的返回值为fallback Fragment - 当Suspense未处于suspend时,child为Offscreen,其
props.mode === 'visible'对应beginWork的返回值为Offscreen
Suspense会经历三次beginWork:
- mount时的beginWork返回Offscreen对应fiberNode(props.mode === 'visible')
- 由于unwind流程(render阶段发生错误后的重置流程),第二次进入mount时的beginWork返回fallback Fragment对应fiberNode
- 等待promise状态变化后触发新一轮更新,进入update时的beginWork返回Offscreen对应的fiberNode(props.mode === 'visible')
Hooks的主要工作分为两部分:
- 通过一些途径产生更新,更新会造成组件render
- 组件render时,useState方法会计算num的最新值并返回
在调用useState的update时实际调哦那个的时dispatchSetState.bind(null, book.queue)调用后的工作流程包括三个步骤:
- 创建update实例
- 将update实例保存在queue.pending构造的环状链表中
- 开始调度更新
组件render时回调用useState,其逻辑大体包含一下三个步骤:
- 获取useState对应的hook(mount时为useState生成对应的hook,update时workInProgressHook指向对应的hook)
- 计算最新state
- 返回最新state及dispatchSetState方法
fiberNode.memoizedState: FC对应fiberNode保存的Hooks链表中第一个hook数据 hook.memoizedState: 某个hook自身的数据,不同类型的hook保存了不同类型的数据
- useState: 对于
const [state,dispatch] = useState(initialState),memoizedState保存state的值 - useReducer: 对于
const [state,dispatch] = useReducer(reducer,{}),memoizedState保存state的值 - useEffect: 对于
useEffect(callback,[...deps]),memoizedState保存callback、[...deps]等数据 - useRef: 对于
useRef(initialValue),memoizedState保存{current: initialValue} - useMemo: 对于
useMemo(callback, [...deps]),memoizedState保存[callback(), [...deps]] - useCallback: 对于
useCallback(callback, [...deps]),memoizedState保存[callback, [...deps]],与useMemo的却别是useCallback保存的时callback函数本身,而useMemo保存的是callback函数的执行结果
useContext则不需要memoizedState保存自身数据
Hooks执行流程- FC进入render流程前,确定ReactCurrentDispatcher.current指向
- 进入mount流程时,执行mount对应逻辑,方法名一般为
mount-hookname - 进入update流程时,执行update对应逻辑,方法名一般为
update-hookname - 其他情况hook执行,依据ReactCurrentDispatcher.current指向做不同处理
- useEffect: 回调函数在commit阶段完成后异步执行,所以不会阻塞视图渲染
- useLayoutEffect: 回调函数在commit阶段的Layout子阶段同步执行,一般用于执行DOM相关操作
- useInsertionEffect: 回调函数在commit阶段的Mutation子阶段同步执行与useLayoutEffect的区别在于,useInsertionEffect执行时无法访问对DOM的引用.这个Hook专门为CSS-in-JS库插入全局Style元素或Defs元素而设计
Effect整体工作流程分为三个阶段: 声明阶段、调度阶段(useEffect独有)、执行阶段
useMemo & useCallback前者用于缓存一个值,后者用于缓存一个函数,useMemo利用其缓存变量的特性可以实现与命中bailout策略类似的效果
Refref是reference的缩写,一般用于对DOM元素的引用但任何需要被引用的数据都可以保存在ref中
ref在React内部不支持跨组件传递但是可以使用forWardRef api,使用useImperativeHandle可以自定义ref对外返回的形式来避免ref失控问题
useTransition是基于核心内置Hooks与源码内部的各种机制实现的内置Hooks,作为面向开发者的并发特性useTransition用于以较低优先级调度一个更新.其原理与batchedUpdates方法类似,只是将操作对象从BatchedContext变为ReactCurrentBatchConfig.transition
Transition updates(过渡的更新)是与Urgent updates(急迫的更新)相对的概念,其中:
- Urgent updates指需要立即得到响应,并且需要看到更新后效果的更新(input、click)
- Transition updates指不需要立即得到响应,只需要看到状态过渡前后的效果的更新
transition通过lane模型的entangle(纠缠)机制实现,entangle相关数据结构包括两个:
- root.entangledLanes用于保存发生缠绕的lanes
- root.entanglements长度为31位的数组,每个索引位置保存一个lanes用于保存root.entangledLanes中每个lane都与哪些lanes发生纠缠
相对于useTransition决定哪些状态更新是低优先级更新,当开发者无法访问触发状态更新的方法(使用第三方库时)此时可以使用useDeferredValue
useDeferredValue接收一个状态并返回该状态的拷贝,当原始状态发生变化后拷贝状态会以较低的优先级更新